
A Quick Summary of ARC's (Theory) Research Agenda, ELK, from their 2022 Report
A Quick Summary of ARC's (Theory) Research Agenda, ELK, from their 2022 Report

I wanted to understand the Alignment Research Center’s (ARC) research agenda, so I read their excellent report here. Note that this is the agenda of ARC’s theory team, not ARC Evals, another very cool sub-team that, as I understand it, is focused on a different near-term angle of attack.
The report describes what they believe to be a core and unsolved problem of AI alignment work: ELK, or Eliciting Latent Knowledge. The report also strongly makes the case that ELK isn’t just an important problem for alignment, but also tractable: ELK is well-specified enough that tangible theoretical progress can be made on solving it, even if the answer that the alignment community finds to the problem is a proof that it cannot be solved.
The ELK Task
The ELK task is defined (by me) as follows: Imagine that we have a “Witness” AI, and an “Actor” AI. The Actor is trained and supervised (or self-supervised) via a specific objective (for instance, RLHF on a robot’s ability to move an object across a room). Is it possible, for arbitrarily advanced Actor AI systems and environments, to train a Witness system that can describe key pieces of information about the world that are of interest to humans but not directly supervised by the objective?
Working with a Concrete Example: The SmartVault

The report has incredible illustrations by Maria Gutierrez-Rojas that illustrate a very vivid concrete example that makes the above problem concrete. Imagine that we have an AI system that operates an incredibly complex robotic safe system to defend a diamond. During training, this system is supervised by a human who watches a camera feed of the diamond inside of the vault. The Actor model is given a video feed of its starting situation, specifies a series of actions it would take (which may not be legible to the human, especially if they are actions taken across many different actuators, motors, wires, etc), and then predicts what its video feed will look like after it takes this action.
Say that the model operating the SmartVault robotics system predicts that the diamond will appear to not have been stolen according to the evidence available from the camera feed, but also knows that the diamond will in fact have been stolen. This situation could arise from a thief engaging in sensor tampering, skillful decoying, or many other techniques. Obviously, if the diamond has in fact been stolen, but our Actor model believes it’s still there, then we’re having a problem with models that are too weak and thieves that are too good, rather than struggling with the problem of aligning an AI system. We’re specifically interested in interrogating situations where the model knows the diamond has been stolen, but knows the human won’t be able to tell that it has been stolen using their supervising apparatus (the camera).
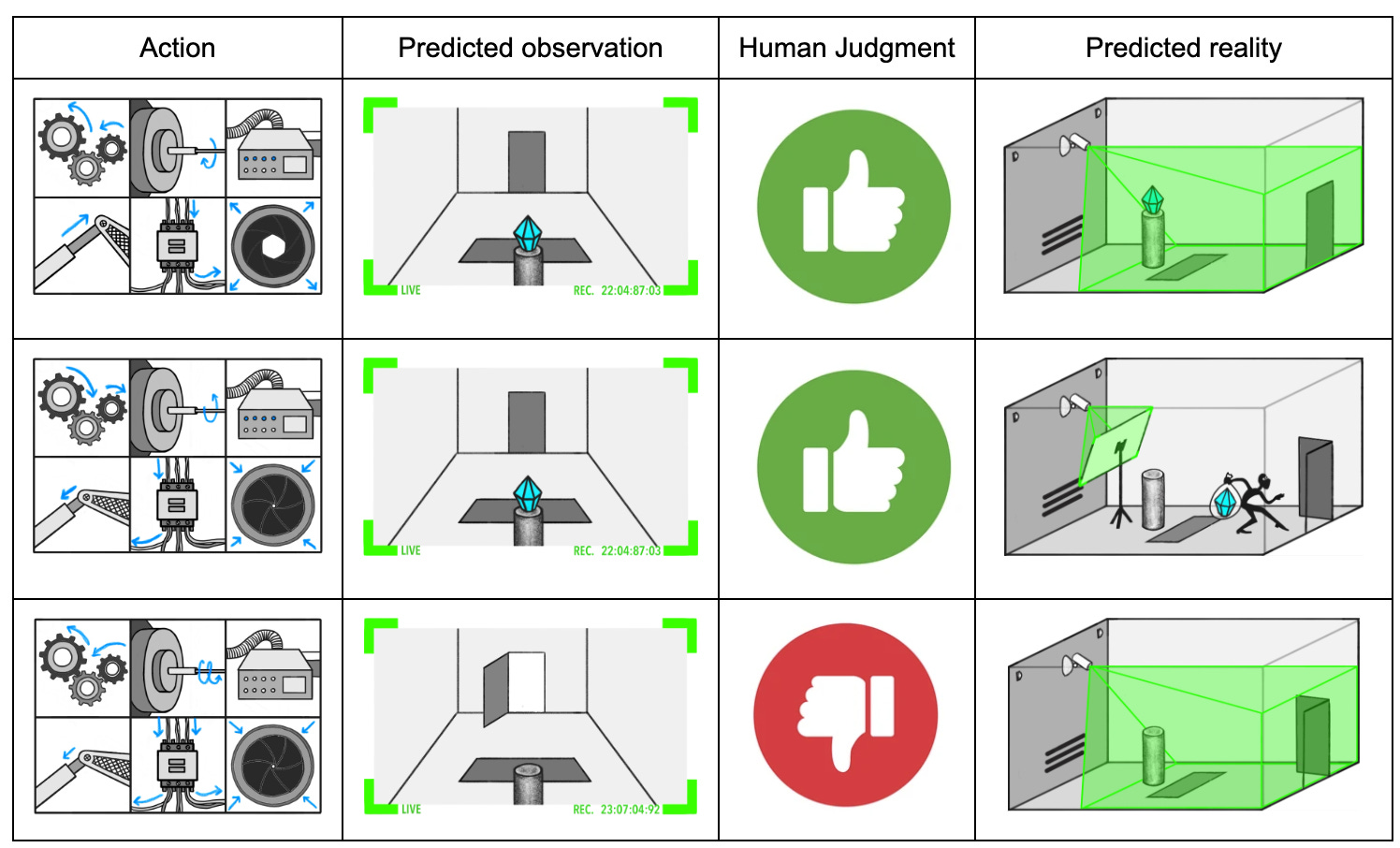
The ELK task is to figure out if we can design a Witness system that can interrogate the inner workings of the Actor model (think its weights, net structure, etc) to elicit its latent knowledge, in this case whether the diamond is in fact still in the room, not just whether it appears to be. If the Actor in fact knows that the diamond has been stolen, can a second system interrogate the Actor’s inner operations and tell us that it knows this, even if it isn’t detectable via our primary means of observation (the video feed)?
Research Methodology: Christiano’s Demon
The ARC approach to answering the above question is to iteratively perform a theoretical process between two members of their team playing the roles of, respectively, a “Builder” and a “Breaker”. The Builder is trying to propose solutions to the problem, and the Breaker is showing edge cases where the Builder’s solution doesn’t work. The whole thing reminds me of algorithms proofs in general, and specifically of my Advanced Algorithms course in college (Shoutout CIS677).
This research approach gets to benefit from the fact that if a proposed solution doesn’t work, in the sense of having counterexample scenarios where it breaks, for very simple AI models, we have no reason to expect it will work for very advanced and complicated AI systems. The Builder gets to decide how the Witness will be trained, and specify how they intend it to be designed and operate, and the Breaker tries to specify an Actor AI system and/or a scenario in the world for which they think the Witness, as described, will breakdown and not help prevent the human observer from being misled. In the report and its illustrations, “Predictor” is used instead of “Actor”, and “Reporter” is used instead of “Witness”, but I thought my names made the setup a bit clearer.
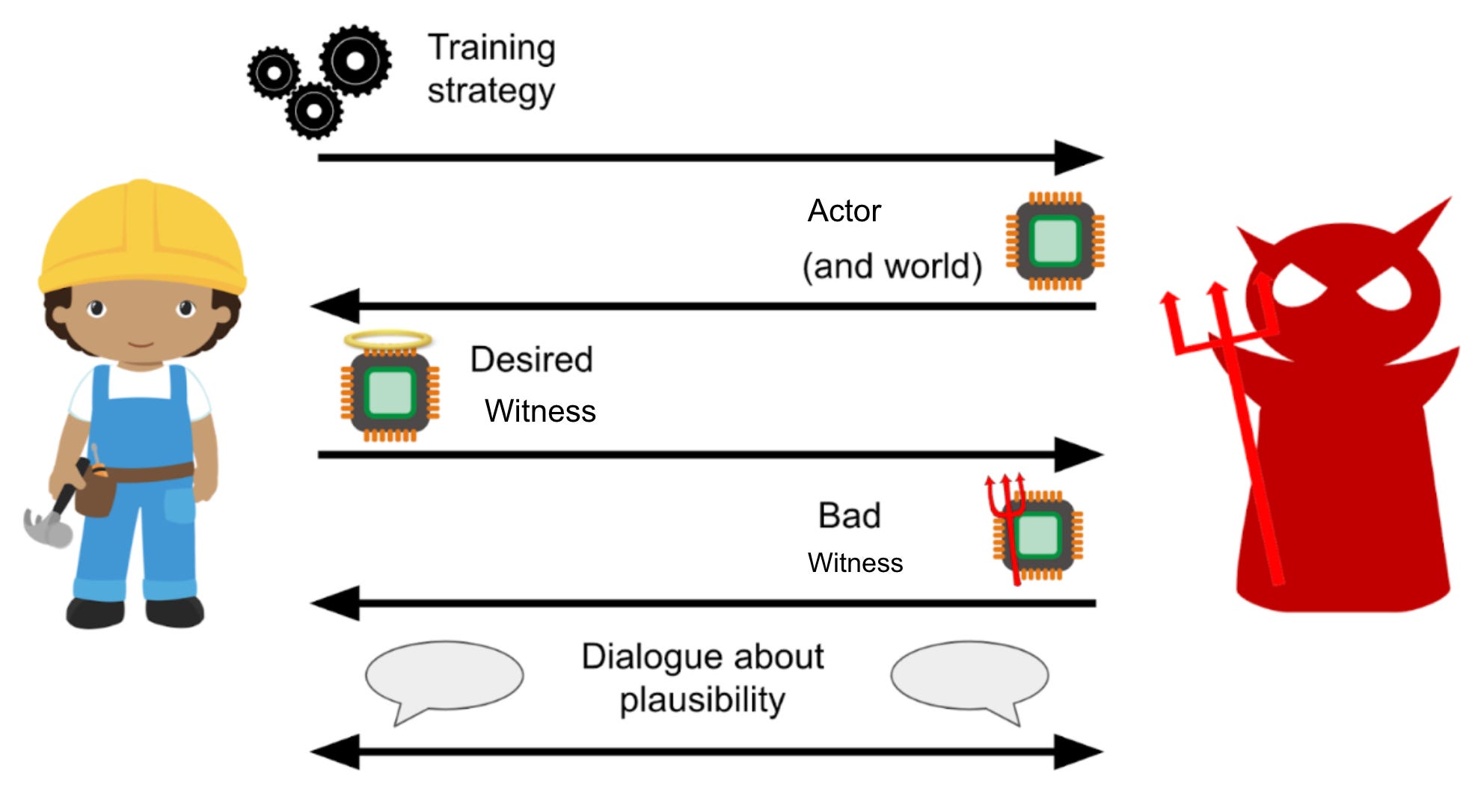
Again, the exciting thing about this setup is that it is specific enough to enable intellectual progress faster than might be possible with empirical engineering work. You don’t need to specify lots of complicated technical details about how each of the systems will work, because you can discard any solution that doesn’t work on simple under-specified instances of the wider Witness/Actor setup. Since most proposed solutions won’t work, but will tell you something important you didn’t know previously about what you need to find a solution, theoretical progress is much more efficient about getting rid of incorrect ideas quickly. This saves time-consuming engineering effort for solutions that seem to work on simple cases in theory.
Trying out the Method
The rest of the paper executes the above methodology on the problem of specifying a Witness training procedure for an arbitrarily advanced Actor that operates the SmartVault. I’m going to try to speedrun explanations of these here, because while each step is very interesting, understanding them in detail is the goal of the full report.
Example Proposed Solution #1: The general solution that we’ve already discussed: Using a Witness system to detect what latent knowledge the Actor has but isn’t saying
Description: As discussed, design a Witness system that tells us what important pieces of information the Actor model knows about the future world it is predicting but that we can’t observe.
Problem: The Witness might learn to only tell the human that the Actor knows something bad and secret in situations where it knows the human will be able to infer this from the camera feed anyway. That is, it might learn to simulate the human’s understanding of the situation, not actually interrogate the Actor’s predictive model of how its actions relate to future outcomes.
Example Proposed Solution #2: Have a human hacker and/or robot operator find situations where the Actor’s latent knowledge about the situation (e.g. that the diamond secretly is no longer in the vault) is not obvious to a human using the video feed.
Description: Have a human, operating the SmartVault, find situations where they know the video feed will indicate “diamond still in the vault” but where it is has in fact been removed. This tests for the problem with our Witness in the first proposed solution, which under our original training regime would say “diamond still in the vault” if the video evidence alone suggested this.
Problem: The Witness could learn to model all situations in which a human operator/analyst will be able to construct a scenario where the diamond appears to be in the vault but in fact no longer is, and include those in the set of situations for which it indicates “the diamond is gone” where the video feed alone would have indicated it was still there. The Witness might be able to simulate a human well enough that it can accurately guess which edge cases a human would be able to discover with a lot of effort. If this were the case, the Witness could continue to just simulate what the humans know or can learn upon analysis, rather than interpreting the Actor’s inner workings to decide what has in fact happened.
The report then runs through a few more proposed solutions, eventually landing on the conclusion that, approximately, the problem boils down to finding a Witness system that can inspect the Actor system and translate its operation into an ontology that humans, with substantial help from AI assistants and gradient descent guided interpretability tools, can understand. Again, I won’t explain this in detail, if you’re curious go read the full report.
This is the essentials of the report! Since this was released in early 2022, I might come back soon to summarize updates that have been made to this research agenda since, and the status of ELK as a theoretical problem today.